[Mysql] index 기준
지난 시간에는 index 설정 컬럼과 설정하지 않는 컬럼의 조회 결과를 비교 해봤다. 이번엔 그렇다면 어떤 컬럼에 인덱스를 설정을 해야 하는가? 에 대해 알아보겠다.
인덱스를 만들 때 어떤 기준으로 만들어야 하는가?
-
크기가 큰 테이블만 만든다. 크기가 작은 테이블에는 인덱스나 풀 스캔이나 큰 차이가 없다.
-
기본키 제약이나 유일성 제약이 부여된 열에는 불필요하다.
pk가 부여된 열에는 자동으로 인덱스가 작성되어 있고, 유일성 제약이 붙어있는 컬럼 또한 같다. 이 2가지 제약이 붙은 열에 암묵적으로 인덱스가 작성된 이유는 값의 중복 체크를 하려면 데이터를 정렬해야 하는데 인덱스를 작성해 정렬하는 것이 편리하기 때문이다.
-
카디널리티가 높은 열에 만든다. 카디널리티가 높은 열에 만든다고 했는데, 카디널리티가 무엇 일까?
카디널리티(cardinality)란 해당 컬럼의 중복된 수치를 말한다. 예를 들어 성별, 학년 등은 중복된 경우가 많기 때문에 카디널리티가 낮다고 말한다. 반대로 주민등록번호, 계좌번호 등은 고유의 번호이기 때문에 카디널리티가 높다고 말한다.
인덱스로 최대한 효율을 뽑아내려면, 해당 인덱스로 많은 부분을 걸러내야 한다. 만약 성별을 인덱스로 잡는다면, 남/녀 중 하나를 선택해야 하기 때문에 인덱스를 통해 50% 밖에 걸러내지 못한다. 하지만 주민등록번호나 계좌번호 같은 경우엔 인덱스를 통해 데이터의 대부분을 걸러내기 때문에 빠르게 검색이 가능하다.
카디널리티를 어떻게 알 수 있을까? MySQL 문법인 DINSTINCT를 통해 알 수 있다. (중복한 값 제외)
단일 컬럼 인덱스와 다중 컬럼 인덱스
- 단일 컬럼 인덱스
하나의 컬럼을 인덱스로 설정.
- 다중 컬럼 인덱스
여러 컬럼을 인덱스로 구성. 첫 번째 조건과 이를 만족하는 두번째 조건을 함께 Index 하여 검색 성능 향상을 위해 사용된다. 최대 15개의 컬럼으로 구성 될 수 있다.
단일 컬럼으로 인덱스 구성시 고려사항
- 카디널리티가 높은 컬럼을 인덱스로 설정하는 것이 좋다.
- 조인의 연결 고리가 되는 컬럼을 설정하는 것이 좋다.
- Update가 빈번하지 않은 컬럼을 설정하는 것이 좋다.
- 단일 인덱스 여러개 보다 다중 컬럼 index의 생성을 고려한다.
- 조건절에 자주 사용하는 컬럼은 Index 추가를 고려한다.
그렇다면 여러 컬럼에 인덱스를 구성할 때는 어떤 기준으로 잡아야 하는가?
다중 컬럼으로 인덱스 구성시 고려사항
- UPDATE가 안되는컬럼을 선정
단일 컬럼을 인덱스로 구성되는 기준과 비슷하다.
다중 컬럼으로 인덱스 구성시 기준
다중 컬럼으로 인덱스를 구성할 시 고려해야 할 점은 순서이다. 과연 어떤 기준으로 순서를 정해야 할까?
먼저 고려해야 할 것은 역시 카디널리티이다.
- 카디널리티가 낮은 -> 높은 순으로 구성
- 카디널리티가 높은 -> 낮은 순으로 구성
이 둘중 어느 것이 좋을까를 판단하기 위해 실험을 한 블로그가 있어 참고를 해서 알아보겠다.
테이블 구성 및 데이터 개수
CREATE TABLE `salaries` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
`is_bonus` tinyint(1) unsigned zerofill DEFAULT NULL,
`group_no` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
이렇게 테이블을 구성을 했고, 데이터는 약 1700만개를 생성했다고 한다. 각 컬럼의 카디널리티를 알아보자.
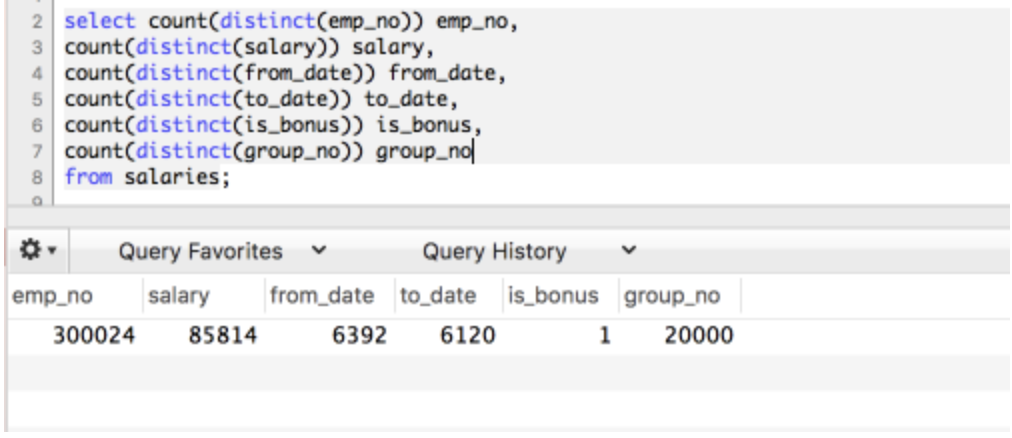
인덱스를 2가지의 형태로 생성 해보자.
CREATE INDEX IDX_SALARIES_INCREASE ON salaries
(is_bonus, from_date, group_no);
CREATE INDEX IDX_SALARIES_DECREASE ON salaries
(group_no, from_date, is_bonus);
첫번째 인덱스는 is_bonus, from_date, group_no순으로 카디널리티가 낮은순에서 높은순 (중복도가 높은 순에서 낮은순으로) 으로, 두번째 인덱스는 group_no, from_date, is_bonus순으로 카디널리티가 높은순에서 낮은순 (중복도가 낮은 순에서 높은순으로) 으로 생성했다.
사용한 쿼리로는,
select SQL_NO_CACHE *
from salaries
use index (IDX_SALARIES_INCREASE)
where from_date = '1998-03-30'
and group_no in ('abcdefghijklmn10494','abcdefghijklmn3968', 'abcdefghijklmn11322', 'abcdefghijklmn13902', 'abcdefghijklmn100', 'abcdefghijklmn10406')
and is_bonus = true;
select SQL_NO_CACHE *
from salaries
use index (IDX_SALARIES_DECREASE)
where from_date = '1998-03-30'
and group_no in ('abcdefghijklmn10494','abcdefghijklmn3968', 'abcdefghijklmn11322', 'abcdefghijklmn13902', 'abcdefghijklmn100', 'abcdefghijklmn10406')
and is_bonus = true;
이렇게 조회를 했다. 이 인덱스 2개를 총 10회로 테스트 했다.
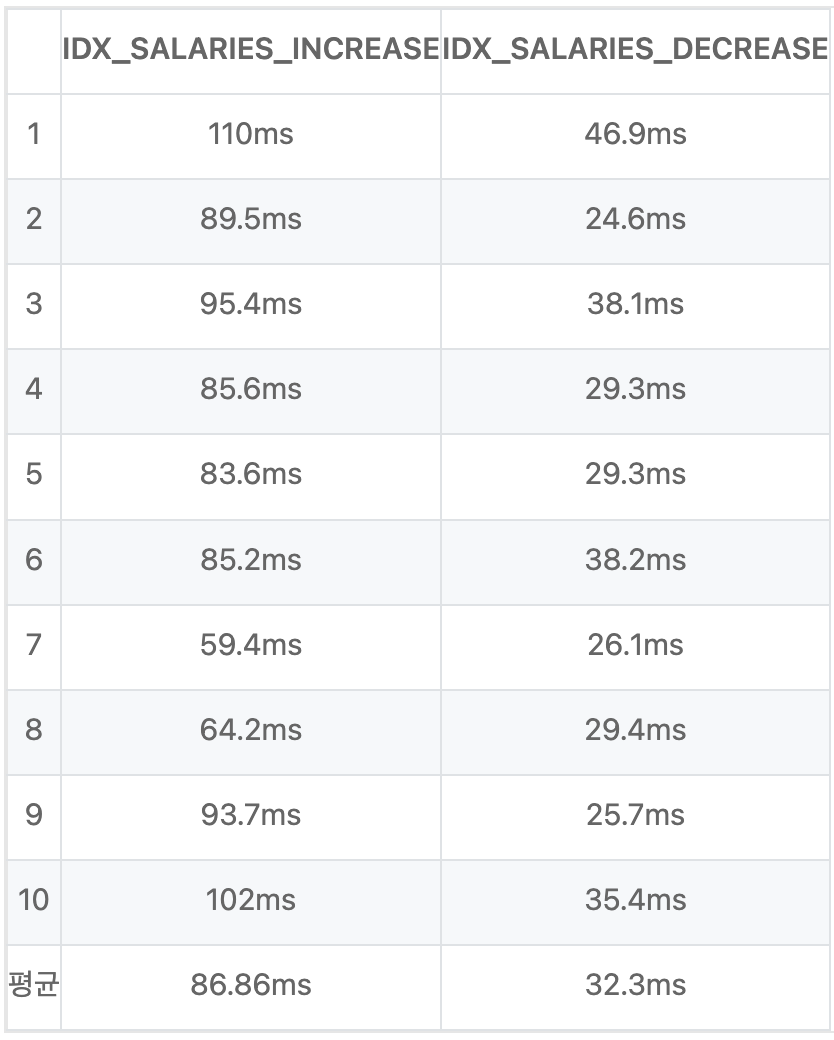
월등한 차이가 나지 않지만, 카디널리티가 높은순에서 낮은순으로 구성하는게 더 성능이 뛰어났다.
이렇게 다중 컬럼으로 구성 되어 있을경우, 꼭 인덱스의 컬럼을 모두 사용하지 않아도 된다. 그렇다면 어떤 것들을 누락 시켜도 되고, 누락되면 안되는 것들을 알아보자.
여러 컬럼으로 인덱스시 조건 누락
이 블로그의 주인 분은 인덱스를 아래와 같이 구성을 하였다.
인덱스 : group_no, from_date, is_bonus
여기서 중간에 있는 ‘from_date’를 제외한 조회 쿼리와 가장 앞에 있는 group_no를 제외한 조회 쿼리를 사용해보겠다.
첫번째 조회 쿼리의 실행계획을 보면

정상적으로 인덱스를 사용이 되고 있는것을 확인할 수 있다. 그리고 filtered가 10% 인 만큼 효율적으로 사용하지는 못했지만, 인덱스를 태울 수 있는 쿼리이다.
두번째 조회 쿼리의 실행계획을 보면
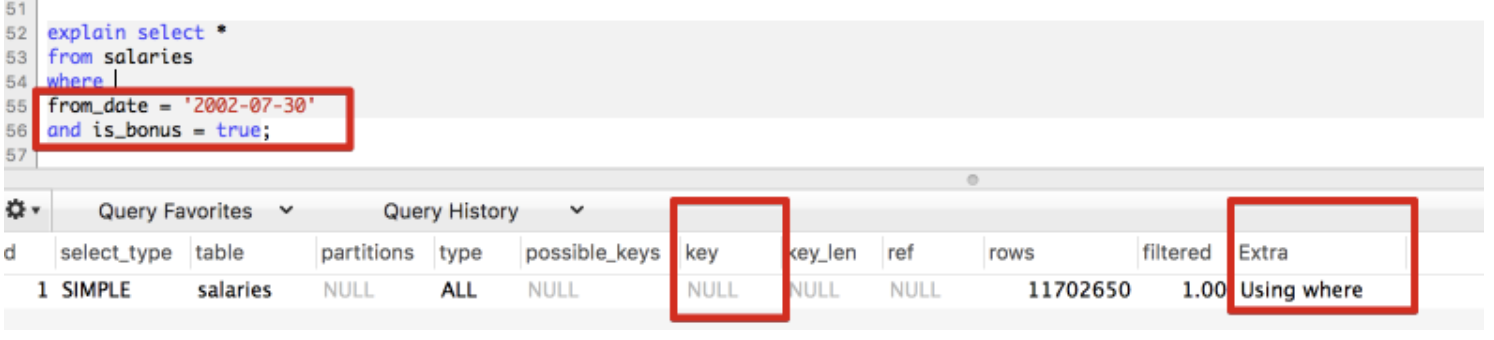
인덱스를 전혀 사용되고 있지 않다.
따라서 다중 컬럼 인덱스를 조회시 최소한 첫번째 인덱스 조건은 조회조건에 포함되어야 한다.
인덱스 조회시 주의 사항
앞에서 보았듯이, 다중 컬럼 인덱스로 조회시 첫번째 인덱스 조건이 조회조건에 포함이 되어야만, 인덱스가 사용된다. 그렇다면 인덱스 조회시 주의 사항은 무엇일까?
-
‘between’, ‘like’, ‘<’, ‘>’ 등 범위 조건은 해당 컬럼은 인덱스를 타지만, 그 뒤 인덱스 컬럼들은 인덱스가 사용되지 않는다.
-
예를 들어, ‘group_no’, ‘from_date’, ‘is_bonus’으로 인덱스가 잡혀있는데 조회 쿼리를 WHERE group_no=XX AND is_bonus=YY AND from_date > ZZ등으로 잡으면 is_bonus는 인덱스가 사용되지 않는다.
-
따라서 범위조건으로 사용하면 안된다.
-
-
반대로 ‘=’, ‘in’은 다음 컬럼도 인덱스를 사용한다.
-
‘in’은 결국 ’=’를 여러번 실행시킨 것이기 때문이다.
-
단, in은 인자값으로 상수가 포함되면 문제 없지만, 서브쿼리를 넣게 되면 성능상 이슈가 발생한다.
-
in의 인자로 서브쿼리가 들어가면 서브쿼리의 외부가 먼저 실행되고, in은 체크조건으로 실행되기 때문이다.
-
-
‘AND’연산자는 각 조건들이 읽어와야할 ROW수를 줄이는 역할을 하지만, ‘or’연산자는 비교해야할 ROW가 더 늘어나기 때문에 풀 스캔이 발생할 확률이 높다.
-
인덱스로 사용된 컬럼값 그대로 사용해야만 인덱스가 사용된다.
-
인덱스는 가공된 데이터를 저장하고 있지 않는다.
-
‘WHERE salary * 10 > 150000;’는 인덱스를 못타지만, ‘WHERE salary > 150000 / 10;’은 인덱스를 사용한다.
-
컬럼이 문자열인데 숫자로 조회하면 타입이 달라 인덱스가 사용되지 않는다. 정확한 타입을 사용해야만 한다.
-
-
null 값의 경우 ‘in null’조건으로 인덱스 레인지 스캔이 가능하다.
마치며
각 인덱스의 조건 및 조회할 때 주의해야할 사항들을 알아봤다. MySQL도 많은 공부가 필요하다는 것을 느꼈다.
댓글남기기